Epic 新语言 Verse 介绍
Verse 语言的由来
Verse 是 Epic 开发的新编程语言,由 Haskell 圈的大佬 SPJ 主导开发。
我们知道,UE 本身使用 C++ 开发,也允许使用 C++ 来对引擎进行扩展,在引擎内部也提供了蓝图作为官方的可视化编程语言。另外,随着用户群体的扩大,市面上也出现了诸如 puerts、unlua 等第三方的脚本语言方案,可以说生态上已经比较完备了。那为什么此时 Epic 还要再发明一个新的语言呢?
关于这个问题,SPJ 在 Haskell eXchange 上做过一个分享,提到了其中的原因。Epic 的老板 Tim Sweeney 经常在鼓吹元宇宙(Metaverse),在他看来,元宇宙有如下的特点:
- 人们可以在一个共享实时 3D 模拟世界中进行社交互动
- 这个世界中有一个开放的经济体系,这个体系有规则但没有某些企业作为霸主
- 这个世界是一个对所有程序员、艺术家、设计师开放的创作平台,而不是一个封闭的花园
- 这个世界不是由一堆编译好的分离的应用集合而成,所有人的代码和内容都能互操作,都能实时动态地更新代码
- 标准是普遍开放的,不被 Unreal 独占,也能使用其他的引擎如 Unity 参与
当然,通用编程语言都是图灵完备的,都可以被用于构建上面的设想,因此,Verse 语言并不是必要的,但是,Tim、SPJ 都觉得目前的语言不够好,不足以方便地实现这样的未来,他们希望能有一个新语言成为元宇宙时代的标准,估计这也是为什么这个语言要叫 Verse。
下图是 Verse 语言希望在元宇宙中的位置,可以看到在这个设想里,Verse 在元宇宙中的地位就是 WWW 中的 Javascript 的地位:

Verse 语言有如下的愿景:
- 可伸缩,能够让数百万素不相识的开发者进行编写,支持数十亿用户去使用他们的产品
- 从一开始就包含事务化的能力,这是在百万开发者之间进行并发处理的唯一合理方案
- 保障跨时间的强交互性,即在编译期就确保模块包含了之前版本的 API
- 对初学者和专家都足够友好
- 可扩展,语言机制会随时间扩展,但不会让之前的代码失效
在元宇宙中,大家实现的不是一个简单的独立产品,而是会对整个虚拟世界产生切实影响的世界组件,想象一下,如果在《头号玩家》那样的虚拟世界中,开发者发布了一个不前向兼容的 API,导致一堆依赖方的交互都突然失效,这将导致怎样的后果。虽然现在谈论这样的未来似乎显得为时尚早,但从中可见 Verse 的愿景背后巨大的野心。虽然元宇宙的火热主要是一场投机分子的狂欢,但不得不承认它本身是对人类未来生活方式的宏大想象。不管 Verse 语言是否真能实现它的愿景,我们还是应当对这样切实的探索抱有尊敬的心情。
Verse 语言的特点
前面提到,Verse 的作者 SPJ 是 Haskell 圈的大佬,这语言自然也有种理论照进现实的感觉,在 Verse Language Reference 文档中总结了其特点有下面这些:
- 静态强类型检查以尽可能避免未捕获的错误
- 支持多种编程范式,例如函数式、面向对象、命令式
- 所有语句都是表达式,因此所有语句都会产生一个值
- 代码执行失败是一种控制流
- 内置的事务化能力,允许用户在失败上下文中进行推测执行,如果执行失败,则表达式产生的作用都不会被提交
- 语言层面的并发能力
在 SPJ 的分享中,他自己总结了 Verse 语言的特点,不过从目前发布的 Verse 语言来看,和他当时说的有一些出入,这里并不是太确定这是内部实现进行了二次封装还是设计本身有改动,下文还是以实际发布的 Verse 语言为准。
Verse 语言部分特点介绍
对于较为完整的语言特性概览,可以参考 Epic 提供的 Verse Quick Reference 文档。在这里仅聊一下 Verse 里个人感觉比较特别的设计,方便让各位对 Verse 提起一点兴趣。
失败控制流
大多数语言使用布尔值 true 和 false 来改变程序执行流,例如在 C++ 中,我们会这样做:
if (index >= 0 && index < vec.size()) {
cout << vec[index];
}
Verse 使用可失败表达式来改变执行流,可失败表达式可能执行成功也可能执行失败,一个典型的例子就是上面提到的数组下标访问。在 Verse 中,这样的代码是编译不过的:
Arr := array{1, 2, 3}
Element := Arr[0]
Log(Element)
编译错误提示为(这个错误提示略显诡异,下一节会说明):
This invocation calls a function that has the 'decides' effect, which is not allowed by its context.(3512)
这里我们需要将代码改为下面这样的形式才能编译通过:
if (Element := Arr[0]):
Log(Element)
这个代码看起来和 C++ 的版本没有太大区别,但 Verse 会在编译期要求一个可失败表达式一定在一个可失败的上下文中执行,即上面的 Arr[0] 如果越界访问,则不会执行 if 中的分支。目前 Verse 规定的可失败上下文有如下几种情况:
if表达式中的判断表达式if (test-arg-block) { … }for表达式中的循环条件判断表达式# 在 Verse 中 test-arg-block 这里可以加入判断终止循环 for (Item : Collection, test-arg-block) { … }- 带有
<decides>作用标记的函数的函数体(下一节详述)IsEqual()<decides><transacts> : void = { … } not运算符的操作对象not expressionor运算符的左操作对象expression1 or expression2option类型的初始化表达式option{expression}
你可能会问,如果这样设计,if 表达式中的条件判断不就有不同的情况了么?有可能是可失败表达式,也有可能是简单的数值比较例如 A < B 。其实在 Verse 里,普通的比较也是一个可失败的表达式,对于 A < B 而言,当 A 小于 B 时成功,否则失败。类似地,判断一个逻辑值(类似布尔值)是否为 true 使用 A? 的形式,这也是一个可失败的表达式,当 A 为 true 的时候成功,当 A 为 false 的时候失败。所以说,Verse 确实是将失败作为一个控制流。
Verse 语言没有提供抛出异常的能力,也没有提供类似 Golang 的 error 或 Rust 的 Result 那样的通用错误表示方式,而是通过失败控制流来影响程序的执行过程。从直观来看,能更好地将错误处理融入到正常的程序执行过程中,但这似乎也使得我们很难在一个地方统一处理错误,语言提供的统一操作只有 option 用于表示一个值有没有,具体这个方案能力是否足够可能还需要再多使用后再做评价。不过这里可以提一个有意思的案例,看一下这个设计带来的一些强大能力。下面的 for 循环表达式想要实现一个扫雷游戏的逻辑,在扫雷游戏中,需要计算一个格子的邻接地雷数量,此时需要遍历整个地图的二维表,对于每一个格子,还需要遍历其周围 8 个格子,根据当前格子的位置,我们需要遍历的格子数量还不一样,例如对于角落的格子,我们只需要遍历周围三个格子即可,这样的逻辑判断写起来还是非常麻烦易错的,但在 Verse 中,这个实现却非常简单清晰:
for:
Y->CellRow : Cells
X->Cell : CellRow
AdjacentX := X-1..X+1
AdjacentY := Y-1..Y+1
AdjacentCell := Cells[AdjacentX][AdjacentY]
Cell <> AdjacentCell
AdjacentCell.Mined?
do:
set Cell.AdjacentMines += 1
首先,Verse 支持类似 range for loop 的语法,可以用 X : Arr 的形式遍历数组,同时支持用 Index->Elem : Arr 的形式在遍历数组时获取其下标,前两行就是在遍历所有地图中的格子。然后 Verse 支持 X := Start..End 的形式遍历一个数字 range,第三第四行就是获取当前格子周围格子的下标,这里包括了自己,因此在第六行进行判断(Verse 中 <> 表示不等于),第七行判断当前邻接的格子是否有地雷,如果有,就对当前格子的邻接地雷数 +1。这里最有意思的是第五行获取邻接格子的时候,这里我们完全没有考虑下标越界的情况,但程序能正确执行,这是因为数组下标访问是一个可失败的表达式,同时,for 循环的条件校验是一个可失败上下文,且这个上下文只对当次循环生效,也就是说,只要条件校验区域这里发生任何失败,当次循环就会跳过,因此这里完全不需要检查下标是否越界,只要越界,就不会执行 for body 中的代码。另外,如之前所述,这里的 <> 和 ? 也是可失败表达式。这里的语义并不是判断他们是否相等而决定是否循环,而是他们是否相等决定了表达式是否成功,失败的时候就不执行 for body 了。这是不是非常有意思。
事务化能力
在上一节中,我们了解到 Verse 语言有一个可失败上下文的概念,并了解到带有 <decides> 说明符的函数的函数体也是一个可失败上下文。这里的 <decides> 是 Verse 的说明符之一,说明符分为四种:
- 类说明符,例如
<abstract>标注一个类是抽象类 - 访问说明符,例如
<public>标注类成员可以被公开访问 - 作用说明符,例如
<suspends>标注一个函数是异步的 - 实现说明符,例如
<native>说明符表示对应 API 是 C++ 实现的
作用说明符本身又被分为两种:
- 独占说明符:可以存在一个或不存在,如果不存在,默认情况下是
<no_rollback> - 附加说明符:可以存在任意个
<decides> 是一个附加说明符,用于标记函数出错时自动回滚,它必须和独占说明符 <transacts> 同时出现。<transacts> 表示函数执行的任何操作都可以回滚。举例而言,下面的 IncScore 就是被标注了可自动回滚:
var MyScore : int = 100
IncScore(Arr: []int)<decides><transacts>: void =
Elem0 := Arr[0]
set MyScore = MyScore + Elem0
Elem1 := Arr[1]
set MyScore = MyScore + Elem1
这里我们可以注意到,由于 IncScore 的函数体是一个可失败上下文,所以我们在里面通过下标访问数组是不需要包一层 if 的。如果这里的任意的一个下标访问越界,这里对 MyScore 的修改就不会生效。例如下面的代码:
OnBegin<override>()<suspends>: void =
Arr1 := array{1,2}
if (IncScore[Arr1]):
Print("IncScore(Arr1) success, MyScore = {MyScore}")
else:
Print("IncScore(Arr1) fail, MyScore = {MyScore}")
Arr2 := array{3}
if (IncScore[Arr2]):
Print("IncScore(Arr2) success, MyScore = {MyScore}")
else:
Print("IncScore(Arr2) fail, MyScore = {MyScore}")
这里有两个事情值得一提。一是 OnBegin 的函数体并不是可失败上下文,因此我们调用 IncScore 的时候需要将其包裹在可失败上下文中,这里简单使用 if 来进行包裹。二是调用 IncScore 的时候没有使用圆括号而是使用方括号,这并不是说 Verse 是使用方括号来表示函数调用,而是 Verse 在语法上区分了不会失败的函数调用和可能失败的函数调用两种情况,前者使用我们熟悉的花括号,后者使用方括号。
此时回过头来看之前我们在非可失败上下文中进行数组下标访问时的错误提示,就显得非常清晰了:
This invocation calls a function that has the 'decides' effect, which is not allowed by its context.(3512)
Verse 其实是认为数组下标访问也是一个函数调用,输入参数是下标值,返回值是数组对应位置元素,这和 Scala 对数组下标访问的处理有异曲同工之妙。不过 Verse 更进一步指出,由于这个下标访问是可能越界的,因此它可能失败,因此这里需要使用方括号语法而非圆括号。那么什么时候编译器能够确定访问下标是不越界的呢?那当然就是访问 tuple 的时候了,就像 C++ 的 tuple 是使用模板参数来在编译期确认访问目标一样,在 Verse 中,tuple 的长度和下标访问也是可以被编译期确定的,因此,下面的代码可以编译通过:
MyTup := (1, 2)
Print("MyTup = {MyTup(0)}, {MyTup(1)}")
回到前面 OnBegin 函数来,根据语义我们也能猜到这个函数的输出,它会是下面这样:
IncScore(Arr1) success, MyScore = 103
IncScore(Arr2) fail, MyScore = 103
这里 IncScore[Arr1] 的两次下标访问都正常,因此对 MyScore 的两次修改都成功了,使其从 100 变为 103。而在调用 IncScore[Arr2] 时,虽然第一次下标访问成功,但是第二次下标访问失败了,此时,整个操作就被回滚了,因此结果不是 106 而是 103。
结合之前 Verse 语言在错误处理方面的设计,似乎语言设计者认为错误处理太过复杂,如果出错,就将之前的操作直接回滚。但这里有一个问题,这里的操作都是本机内存的操作,如果涉及到文件操作如何处理?或者更复杂的情况,涉及到分布式的场景如何处理?例如我需要写两个文件,第一个文件写成功,第二个文件写失败,此时可能开发者还是希望有一个判定错误内容并进行错误处理的方法。
细粒度并发支持
现在很多语言都对并发执行有不同层面的支持,例如 Golang 的 goroutine 和 channel,C# 的 async / await 等,相比于这些较为常见的并发支持,Verse 在语言层面提供了更为细化的并发控制能力。在 Verse 语言中,并发分为结构化和非结构化两种,所谓非结构化并发就是类似很多语言或库使用的 task,启动一个异步的 task,然后可以同步阻塞等待其执行完毕,例如:
MyTask := spawn{Player.MoveTo(Target1)}
MyTask.Await() # 等待执行结束
这样非结构化并发的能力大部分语言都会提供支持,Verse 的特色在于在语言层面对多种并发场景的细分支持,目前总共支持 sync、branch 、 race、rush 四种,它们的区别如下:
sync 会并行执行代码块中的所有表达式,并等待所有表达式执行完毕后,再执行代码块后面的表达式。对于下面的情况而言:
expression0
sync:
slow-expression
mid-expression
fast-expression
expression1
其执行顺序如下图所示:

因为 sync 代码块会等待所有表达式的执行结果,因此其返回值为一个包含代码块中每个表达式返回值的 tuple。没错,在 Verse 中所有东西都是表达式,因此都会有值,包括前面提到的 if 等,sync 代码块和我们这里提到的所有代码块都是表达式,它们都有值。因此,下面这样的写法是合法的:
MyTup := sync:
Foo(0)
Foo(1)
Print("MyTup = {MyTup(0)}, {MyTup(1)}")
branch 会并行执行代码块中所有表达式,不等待它们结束就继续执行代码块后面的表达式。对于下面的情况而言:
expression0
branch:
slow-expression
mid-expression
fast-expression
expression1
其执行顺序如下图所示:

因为 branch 代码块不会等待内部表达式,因此其返回值为 void。
race 会并行执行代码块中所有表达式,当其中任意一个表达式执行结束的时候,race 代码块后的表达式就会执行,race 代码块中其他表达式会被取消。对于下面的情况而言:
expression0
race:
slow-expression
mid-expression
fast-expression
expression1
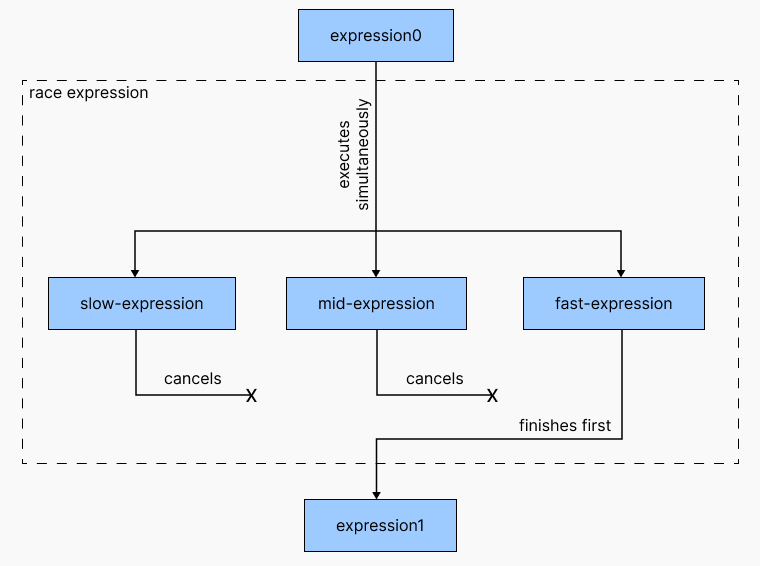
因为 race 代码块在最快的表达式执行结束后就结束,这可能是代码块中任意一个表达式,因此其返回值的类型为所有这些表达式返回类型的兼容类型。
rush 会并行执行代码块中所有表达式,当其中任意一个表达式执行结束的时候,rush 代码块后的表达式就会执行,rush 代码块中其他表达式会像 branch 中的表达式一样继续执行,而不是被取消。对于下面的情况而言:
expression0
rush:
slow-expression
mid-expression
fast-expression
expression1
其执行顺序如下图所示:
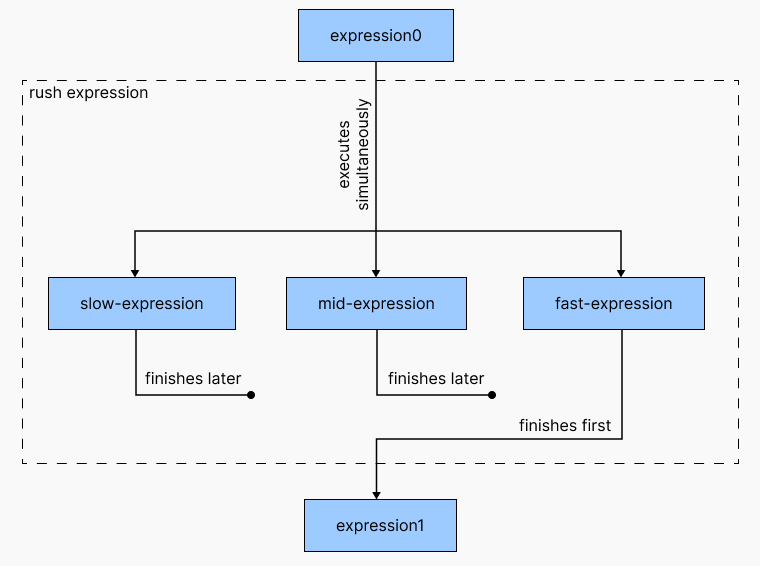
类似 race,rush 代码块也在最快的表达式执行结束后就结束,因此其返回值的类型也为所有这些表达式返回类型的兼容类型。
Verse 对并发的细粒度支持确实相当方便,而且由于在 Verse 中一切都是表达式,所以上面这几种并发控制方式还能混合嵌套使用,覆盖各种复杂场景。
总结
Verse 是一个具有很大野心的新语言,也是一个博采众长的语言,里面可以看到很多现有语言中很好的特性,例如 C# 中的扩展方法,Golang 中的 defer 等等,上面只提到了很少的几个特性。Verse 目前仍然在开发中,非常期待它之后的发展。如果现在想要尝试的话,可以跟随 Your First Verse Program 来搭建实验环境,在 UEFN(Unreal Editor for Fortnite)中使用这个语言。