AI 届新语言 Mojo 要🔥?
Mojo 语言简介
这个标题里放一个 emoji 有点哗众取宠的意思,但真不是我想放,而是 Mojo 这语言自己的官网就长这样 1。而且,这语言的标准文件后缀一个是「.mojo」另一个就是「.🔥」。说实话,这个操作其实挺无聊的,也有点败好感,但如果说这个语言能在完全兼容 Python 的基础上大幅提高执行效率,并且作者是 LLVM 发起人 Chris Lattner 2,是不是突然又有兴趣继续了解它了呢?Mojo 被设计为 Python 语言的超集,并增加了许多特性,包括:
- Progressive types:能利用类型信息获得更好性能和静态检查,但又不强制要求写类型
- Zero cost abstractions:C++ 的核心设计准则,能够避免用户为了性能放弃合理设计的代码
- Ownership + borrow checker:Rust 语言的安全性来源,在编译期避免许多错误的发生
- The full power of MLIR:原生支持对 MLIR 的直接访问,能够从底层扩展系统
除此之外,Mojo 还有很多别的特性,如编译期元编程、自动参数选择等等,在这篇文章中我们将略窥一二。在这之前,还是让我们先来看看为什么我们需要一个新语言吧。
为 AI 而生的语言
在 Mojo 这个语言的介绍中反复提到 AI,官网也说它是「a new programming language for all AI developers」。那么为什么 AI 开发需要一个新语言呢?首先,我们知道在 AI 届具有统治地位的语言就是 Python,Python 是一个语法简单清晰,容易上手,且灵活度很高的语言,深受广大程序员喜爱,XKCD 上有就这么一幅漫画 3:

当然,受人喜爱的语言有很多,Python 成为 AI 届的统治语言除了本身易用之外,也有惯性的因素。由于 Python 上机器学习相关的库多,因此机器学习从业者用的就多,这又反过来令新的机器学习相关库优先为 Python 提供接口,进一步加强了其统治地位。因此,为了逐步渗透这个用户群,Mojo 兼容 Python 是很正确的一个选择。Mojo 不仅承诺语法是 Python 的超集,并且它还能直接调用 Python 的库,这意味着 Mojo 不需要从零开始构建自己的生态,本身就可以用上繁荣的 Python 生态了。
虽然 Python 很好,但它有一个众所周知的问题,那就是太慢了。而机器学习本身又需要繁重的计算,因此 Python 生态中大量库的底层其实都是用高性能的语言(如 C/C++)进行实现,然后再提供一个 Python 接口供用户调用,典型的如 numpy 这种数学库。在这种情况下,Python 事实上是被作为一个胶水语言来使用,这造成了开发的碎片化,如果一个用户只是简单调一下库那还好说,但一旦到了工业界,开发过程中不可避免地就要涉及一些底层库的修改,甚至直接换语言来实现同样的功能以提高性能,这种割裂不止增加了开发成本和精神负担,而且考虑到众多擅长 C/C++ 语言的开发者也并不是 AI 领域专家,这种开发人员能力的不适配也对整个 AI 生态的发展形成了一定阻碍。
因此,Mojo 的目的就是要在 Python 生态的基础上,让用户能用一个语言,从使用易用的接口,到开发复杂的库,再到实现底层黑科技,统一实验和生产环境所用的语言。为了实现这个目的,Mojo 扩展了 Python 语法,支持了紧凑的内存布局,并引入了一些现代的语言特性(例如 Rust 的安全性检查),使得这个语言能够渐进式地在 AI 届立足。说起来 Chris Lattner 在这方面可以算是经验丰富了,不管是在 gcc/msvc 的统治下实现 clang,还是在 objective-c 的统治下为苹果实现 swift,都是一个逐步蚕食对手市场的过程。
Mojo 长什么样
说了这么多,该来看看 Mojo 长什么样了。现在 Mojo 还不能直接下载使用,如果想要尝鲜,需要在官网申请,然后在 playground 页面中试用,这是一个基于 Jupyter 的页面,可以混合笔记和可执行的 Mojo 代码。
前面提到,Mojo 的语法是 Python 的超集,因此 Mojo 的 Hello World 也跟 Python 一样简单:
print("Hello World") #> Hello World
与 Python 一样,Mojo 也使用换行符和缩进来定义代码块:
fn foo():
var x: Int = 1
x += 1
let y: Int = 1
print(x, y) #> 2 1
foo()
上面的代码中使用 var 来声明变量 x,使用 let 来声明了不可变量 y。Mojo 像很多较新近的语言一样,让不可变量的声明变得简单,以鼓励开发者使用不可变的量。另外注意到这里定义函数使用了 fn 而非 Python 的 def,这是因为 Mojo 希望在兼容 Python 的基础上加入编译期的检查和优化,而 Python 过于动态的语法很难支持这一目标,因此,Mojo 同时支持使用 fn 和 def 两个关键字来声明函数,对于调用者来说,这两种方法声明出来的函数没有什么区别,但对于实现者来说,可以将 fn 看作「严格模式」下的 def,例如下面的代码会编译错误(如果改成用 def 则不会出错):
fn foo():
x = 1
print(x)
# error: Expression [12]:6:5: use of unknown declaration 'x', 'fn' declarations require explicit variable declarations
# x = 1
# ^
虽然官方承诺 Mojo 的语法是 Python 的超集,但目前 Mojo 还在开发中,很多 Python 语法都还不支持,例如目前连 Python 的 class 都无法被编译通过:
class MyClass:
def foo():
pass
# error: Expression [15]:17:5: classes are not supported yet
# class MyClass:
# ^
不过,Mojo 现在先提供了另一个用来组织数据的关键字 struct,相比与 class,struct 更加静态可控,便于优化。一方面,struct 支持类似 Python class 风格的函数声明和运算符重载。而另一方面,struct 又类似于 C++ 的 struct 和 class,内部的成员在内存中紧凑排布,而且不支持在运行时动态添加成员和方法,便于编译期进行优化,例如:
struct MyIntPair:
var first: Int
var second: Int
fn __init__(inout self, first: Int, second: Int):
self.first = first
self.second = second
fn __lt__(self, rhs: MyIntPair) -> Bool:
return self.first < rhs.first or
(self.first == rhs.first and
self.second < rhs.second)
let p1 = MyIntPair(1, 2)
let p2 = MyIntPair(2, 1)
if p1 < p2: print("p1 < p2") #> p1 < p2
虽然有点不同,但整体上看起来还是非常熟悉的对吧。说到这里,有一点需要提醒各位注意,尽管 Mojo 之后会令语法成为 Python 语法的超集,但其语义则有时会和 Python 不同,这意味着 Python 的代码直接拷到 Mojo 里可能会出现编译通过但执行结果不同的情况,这里简单提一个比较常见的例子:函数传参。在 Python 中,函数传参的语义类似于 C++ 的传指针,在函数内部虽然不能更改调用者指向的对象,但可以改变该对象内部的状态,例如下面的代码:
def foo(lst):
lst[0] = 5
print(lst)
x = [1, 2, 3]
foo(x)
print(x)
在 Python 中,这段代码打印出来的结果是两次 [5, 2, 3]。但在 Mojo 中,使用 def 定义的函数默认的传递逻辑是复制值,也就是说,尽管在函数中能够修改参数内部的状态,但修改对于调用方来说是不可见的,因此上面这段代码在 Mojo 中打印的结果是 [5, 2, 3](foo 内部)和 [1, 2, 3](foo 外部)。
除了语法像 Python,Mojo 非常务实的一点在于它构建于 Python 的生态之上。因此即便 Mojo 还没能完整支持 Python 的语法,它还是优先支持了对 Python 库的调用,以便让开发者能受益于庞大完善的 Python 的生态。例如下面的代码就使用了 Python 的 numpy 库:
from PythonInterface import Python
let np = Python.import_module("numpy")
ar = np.arange(15).reshape(3, 5)
print(ar.shape) #> (3, 5)
博采众长又有所创新
Mojo 作为一个新语言,广泛吸收许多现代的程序语言设计思想,例如 Rust 的所有权和借用检查,以此提升代码的安全性。在 Mojo 中,使用 fn 定义的函数的参数默认传的是不可变的引用,即「借用」,调用方仍然拥有其所有权,因此在函数内部不可以对参数进行修改。Mojo 提供了一个 borrow 关键字来标注这样的参数传递情况,对于 fn 来说是可以省略的,也就是说下面 foo 函数中两个参数的传递方式相同:
fn foo(borrowed a: SomethingBig, b: SomethingBig):
a.use()
b.use()
在 Rust 中,传参的默认行为是移动,如果需要借用则需要在传入时加上 &,这两种方式倒是没有太大的优劣之分,Mojo 的行为可能更接近于 Python 这类高级语言的习惯。如果想要修改传入的参数,则需要手动注明 inout,例如:
fn swap(inout lhs: Int, inout rhs: Int):
let tmp = lhs
lhs = rhs
rhs = tmp
fn test_swap():
var x = 42
var y = 12
print(x, y) #> 42, 12
swap(x, y)
print(x, y) #> 12, 42
test_swap()
按道理说,Mojo 应该像 Rust 一样规避一个变量同时被可变和不可变借用,也应该规避同时被可变借用,但目前 Mojo 编译器似乎还没实现这一特性,例如下面的代码还是能编译通过的:
var x = 42
swap(x, x)
从这也可以看出 Mojo 确实还处在比较早期的发展阶段。
另一个重要的内存安全概念是对象的所有权,当一个函数获取了对象的所有权后,调用方就不应该再去使用这个对象了,例如我们实现了一个只支持移动的类型 UniquePtr:
struct UniquePtr:
var ptr: Int
fn __init__(inout self, ptr: Int):
self.ptr = ptr
fn __moveinit__(inout self, owned existing: Self):
self.ptr = existing.ptr
fn __del__(owned self):
self.ptr = 0
同时,我们有两个函数,其中,use_ptr 使用了前面提到的 borrow 关键字,借用了 UniquePtr 对象,而 take_ptr 则使用 owned 关键字,指明它需要获取传入对象的所有权。那么,在调用 take_ptr 的时候,我们就需要在参数后面加上 ^ 后缀,用来表明我们将所有权转移给 take_ptr:
fn use_ptr(borrowed p: UniquePtr):
print(p.ptr)
fn take_ptr(owned p: UniquePtr):
print(p.ptr)
fn test_ownership():
let p = UniquePtr(100)
use_ptr(p) #> 100
take_ptr(p^) #> 100
test_ownership()
因此,如果我们将 use_ptr 和 take_ptr 的调用顺序调换一下,就会出现编译错误:
fn test_ownership():
let p = UniquePtr(100)
take_ptr(p^)
use_ptr(p) # ERROR!
test_ownership()
# error: Expression [13]:23:12: use of uninitialized value 'p'
# use_ptr(p) # ERROR: p is no longer valid here!
# ^
Mojo 的另一个强大之处在与它让对 MLIR 的操作变得更简单。MLIR 全称是 Multi-Level Intermediate Representation,是一个编译器开发框架,它存在的目的是通过定义多种方言来逐级将代码转换为机器码,以降低编译器的开发成本。在 MLIR 之前,一个广为人熟知的 IR 是 LLVM IR,一个语言的编译器作者可以通过将自己的语言编译为 LLVM IR 来接入 LLVM 的工具链,使得编译器作者不需要关心底层具体硬件的差别,实现了对底层编译工具链的复用 4:
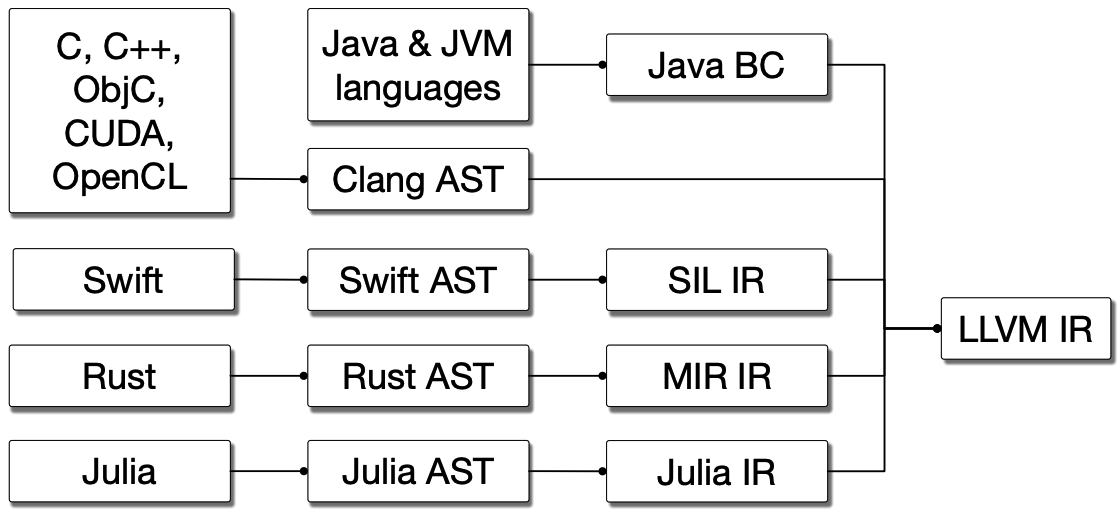
但 LLVM IR 层级过低,难以进行特定于语言本身的优化,从上面的图中也能看出,各个语言为了实现语言本身的优化,都在编译为 LLVM IR 之前加入了自己的 IR。另外 LLVM IR 扩展起来也非常困难,难以适应复杂异构计算的要求,而异构计算在 AI 开发中又非常普遍。MLIR 相比与之前的 IR,更加模块化,仅保留了一个非常小的内核,方便开发者进行扩展。很多编译器将代码编译为 MLIR,而 Mojo 提供了直接访问 MLIR 的能力,这使得 Mojo 能够受益于这些工具。更多关于 MLIR 的内容可以参考这一系列文章:编译器与中间表示: LLVM IR, SPIR-V, 以及 MLIR,这里就不作过多赘述,我们主要关注在 Mojo 中可以如何操作 MLIR。举例而言,如果我们希望实现一个新的 boolean 类型 OurBool,我们可以这样实现 5:
alias OurTrue: OurBool = __mlir_attr.`true`
alias OurFalse: OurBool = __mlir_attr.`false`
@register_passable("trivial")
struct OurBool:
var value: __mlir_type.i1
fn __init__() -> Self:
return OurFalse
fn __init__(value: __mlir_type.i1) -> Self:
return Self {value: value}
fn __bool__(self) -> Bool:
return Bool(self.value)
这里定义了一个类型为 OurBool 的类型,里面有一个直接使用 MLIR 内置类型 i1 的成员 value 6。在 Mojo 中,我们可以通过 __mlir_type.typename 的形式来访问 MLIR 类型。接着,我们为这个类型提供了两个构造函数,默认情况下构造为 OurFalse 也可基于传入的参数进行构建。最下面的 __bool__ 也和 Python 的 __bool__ 一样,用于使该类型具有和内置 boolean 类型的性质,此时我们可以这样使用它:
let t: OurBool = OurTrue
if t: print("true") #> true
除了使用 MLIR 之外,Mojo 甚至可以允许开发者使用 MLIR 实现逻辑,例如下面的代码中通过应用 MLIR 的 index.casts 7 操作来实现类型转换,然后再通过 index.cmp 8 对值进行比较:
# ...
struct OurBool:
# ...
fn __eq__(self, rhs: OurBool) -> Self:
let lhsIndex = __mlir_op.`index.casts`[_type : __mlir_type.index](
self.value
)
let rhsIndex = __mlir_op.`index.casts`[_type : __mlir_type.index](
rhs.value
)
return Self(
__mlir_op.`index.cmp`[
pred : __mlir_attr.`#index<cmp_predicate eq>`
](lhsIndex, rhsIndex)
)
基于封装好的 __eq__ 方法,我们可以很容易实现 __invert__ 方法:
# ...
struct OurBool:
# ...
fn __invert__(self) -> Self:
return OurFalse if self == OurTrue else OurTrue
此时,我们就可以对 OurBool 类型的对象使用 ~ 操作符了:
let f = OurFalse
if ~f: print("false") #> false
通过这个简单的例子我们可以看出,在 Mojo 中,开发者可以通过访问 MLIR 来实现和内置类型同等高效的类型。这使得开发者可以在 Mojo 上为新硬件的数据类型封装高效简单的 Mojo 接口而不需要切换语言。虽然大部分开发者并不需要接触 MLIR,但 Mojo 为更深入和更底层的优化提供了充分的可能性。
总结:为 AI 而生而不止于 AI
虽然 Mojo 反复强调它是为 AI 设计的新语言,但以目前 Mojo 的设计方向来看,它的发展前景并不止于 AI。本质上 Mojo 提供了一个能够兼容 Python 生态的高性能语言,且这个语言可以让 Python 开发者几乎无痛地切换过去,那 Python 开发者何乐而不为呢?对于使用 Mojo 的开发者来说,上层业务可以将 Mojo 当 Python 一样使用,享受到简明的语法带来的高开发效率,当出现性能瓶颈的时候,也不用切换语言去进行优化,直接使用 Mojo 重构模块即可。虽然现在还没法在生产环境中验证这个想法,但这个未来听起来确实非常美好。关于 Mojo 和 Python 开发性能的对比,还可以通过 Mojo 发布会上播放的 Jeremy Howard demo for Mojo launch 这个视频来感受一下。
目前 Mojo 还在比较早期的阶段,不仅许多语言特性都还没实现,而且连本地开发的套件都没有提供。不过其发展路线和设计思路都非常务实 9,又有一个足够专业的领导者和公司作为背景支撑,可以说是未来可期,也非常希望这个语言能在其他领域得到更广泛的应用。