图形学入门(三):基础着色
在掌握了上一篇文章的知识之后,我们现在可以通过逐个绘制三角形面组合出一个模型了。但是我们现在绘制出来的结果看起来是一个色块,效果不太自然。在现实中,我们看到物体是因为这个物体反射了光线,而在这个过程中,根据物体形状以及与光线的相对位置关系,物体的表面总会呈现不同的明暗效果。这种明暗的变化使我们感觉这个物体是「立体的」。也就是说,我们更希望看到下图 1 中右侧的渲染效果而非左侧的渲染效果:
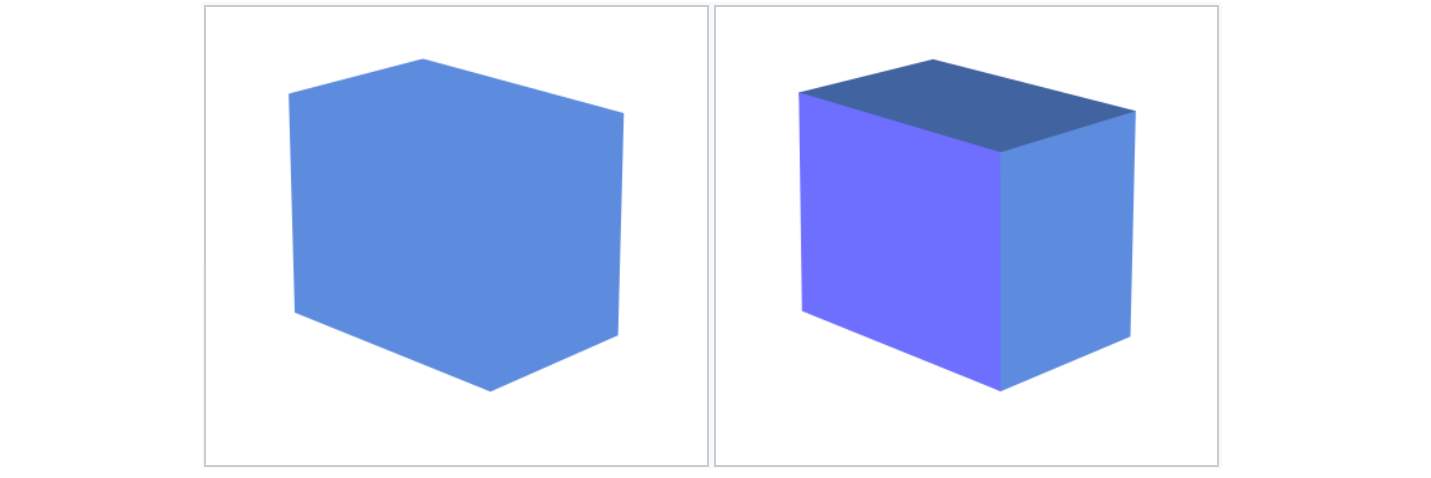
在计算机图形学中,着色(Shading)1 表示在三维场景中基于模型表面与光源的角度、与光源的距离、与相机的角度等因素,来改变多边形颜色的过程,以此来生成具有真实感的效果。这里说的「真实感」是指类似照片拍摄的效果。
Phong 反射模型
真实的符合物理规律的光照极其复杂,想要在计算机中正确模拟出这个效果非常困难。为了能在计算机中快速进行渲染,我们需要采用一些方法简化这个计算过程,现在被广泛使用的着色模型叫 Phong 反射模型(Phong Reflection Model)2。这个模型对现实中光照反射规律进行近似模拟,将物体对光线的反射拆成三个分量,分别是:漫反射光(Diffuse)、镜面高光(Specular)和环境光(Ambient)。在后面的讨论中我们会看到,这个模型本身虽然不是一个物理模型而是一个经验模型,但它也符合一些基本的物理规律,并可以很好地模拟相当广泛的视觉场景。
Phong 反射模型基于这样的观察:
- 一个物体表面越粗糙,其对光线的反射就越分散,而这部分反射的光构成了物体本身的基础颜色,这部分颜色用漫反射分量 $L_d$ 表示
- 一个物体表面越光滑,其对光线的反射就越集中,就越会在某些位置上呈现比较集中明亮的高光,这部分颜色用镜面反射分量 $L_s$ 表示
- 如果场景中有光源,那么即便一个物体没有直接被光源照亮,我们也还是看到这个物体。事实上,这部分表面接收到了来自四面八方的间接光照,这部分颜色用环境光分量 $L_a$ 表示
这个观察基本上也符合我们的认知,而这三个分量叠加的效果看起来还是相当可信的,如下图所示 2:

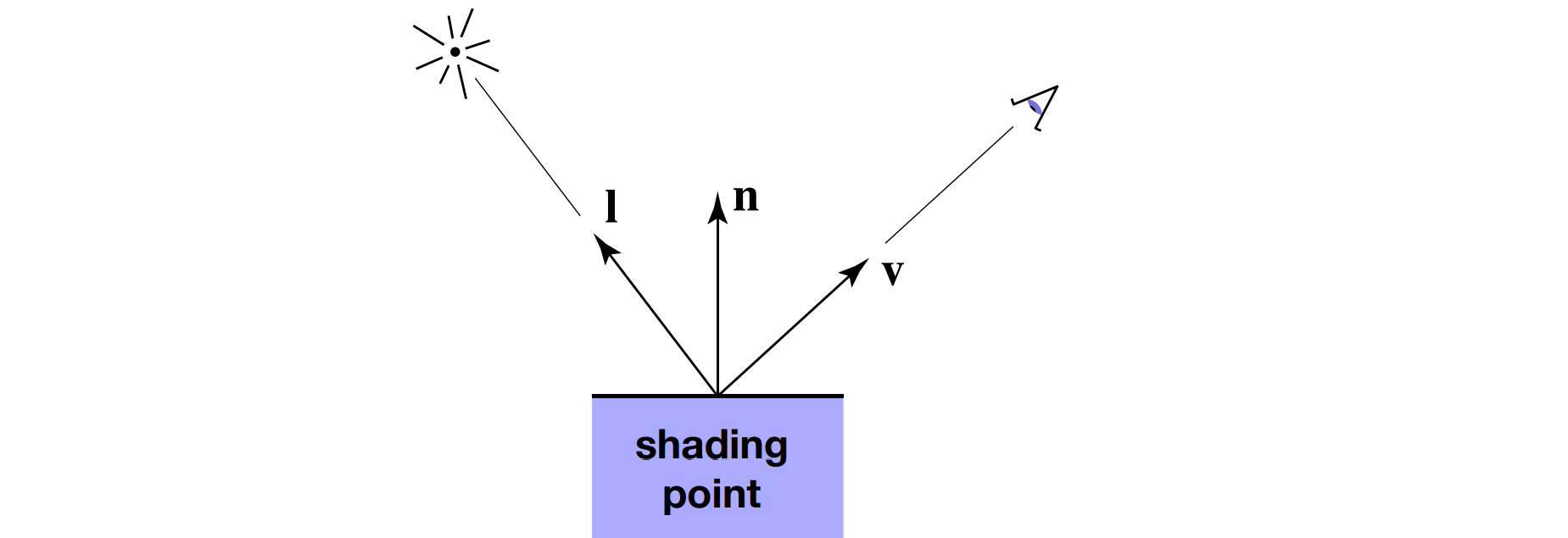
需要说明的是,Phong 反射模型是一个局部模型,所谓「局部」是指,在计算某个点(我们称之为着色点)的颜色时我们只考虑这个点本身的属性以及这个点和光线的关系,和其他物体无关。「非局部」的典型例子就是阴影,阴影的计算不仅需要考虑当前着色点,还需要考虑着色点与光源之间的遮挡物。因此 Phong 反射模型的计算中并不会产生阴影。具体来说,我们在计算一个点的颜色时,我们可用的局部信息有如下几部分:
- 观察方向 $\hat{v}$
- 每个光源的方向 $\hat{l}$
- 当前点的表面法线方向 $\hat{n}$
- 当前点的表面材质参数(例如颜色、光泽度等)
其中,$\hat{v}$、$\hat{l}$、$\hat{n}$ 都是单位向量。
漫反射分量
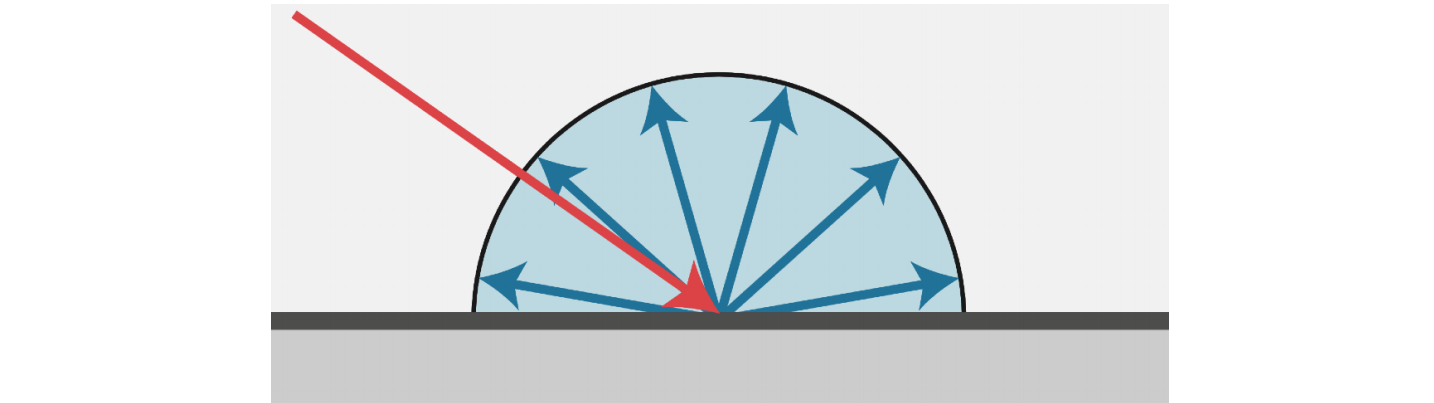
我们知道,一个粗糙的物体表面会将入射的光向周围各个方向反射,我们称之为漫反射,如下图 3 所示:
我们前面提到,漫反射的分量构成了物体的整体颜色,它是 Phong 反射模型中最重要的一部分。我们知道,物体表面呈现不同的颜色是由于不同的表面会吸收不同波长的光并反射其他的光,我们用漫反射系数 $k_d$ 描述这种现象,如果 $k_d = 1$,那么物体本身不吸收对应颜色的光,对其进行完全的反射,如果为 $0$,那么说明完全吸收了对应颜色的光。而这个入射的光,我们则用 $I$ 表示。另外根据我们日常的观察也会发现,如果一个表面正对着光源,那么这个表面看起来就会比较亮,如果背对光源,这个表面看起来就会比较暗。如下图 3 所示,当一个物体表面正对光源时,它能接收到光源的全部能量,当它没有正对光源时,接收到的能量就变少了。这个能量的具体比例可以用平面法线方向 $\hat{n}$ 和光源方向 $\hat{l}$ 的夹角 $\theta$ 的余弦值来确定:
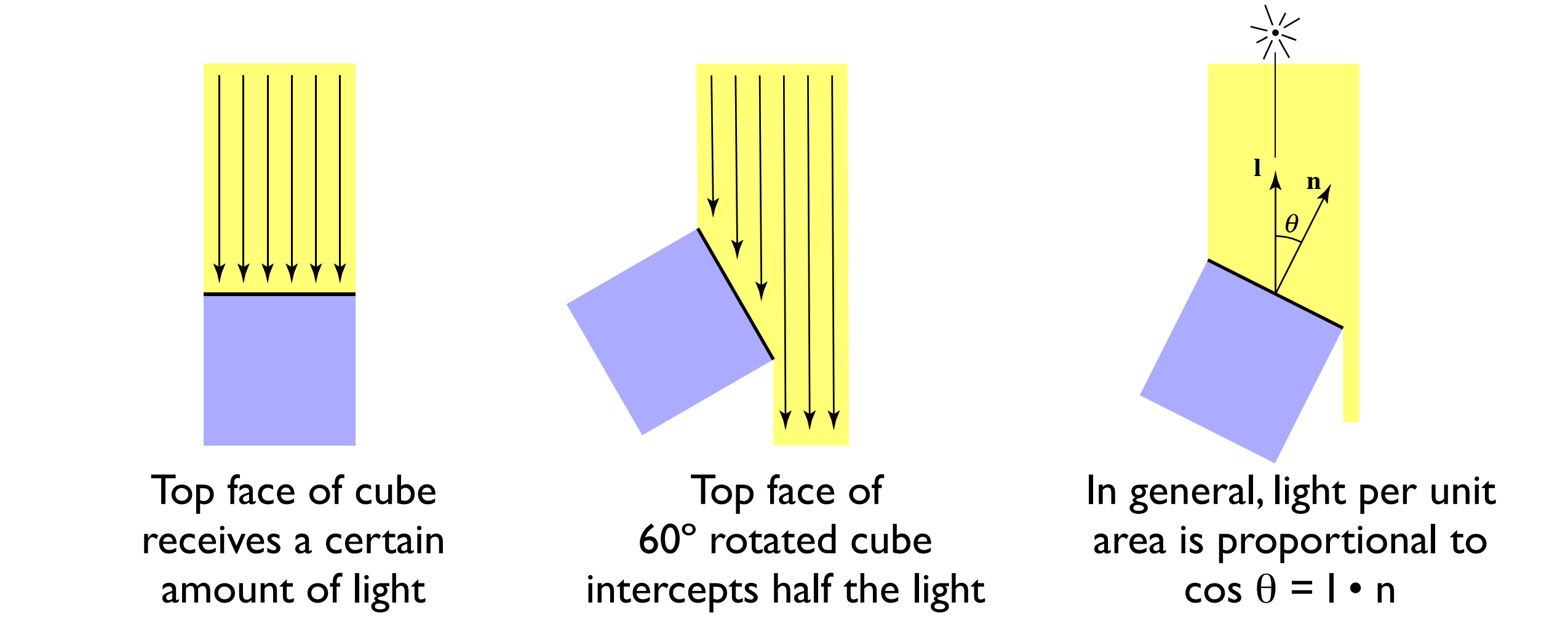
又由于 $\hat{n}$ 和 $\hat{l}$ 是单位向量,我们可以直接对其进行点乘来获取到这个余弦值,因此,我们的漫反射分量 $L_d$ 表示如下:
$$ L_d = k_d \ I \cos{\theta} = k_d \ I \ (\hat{n} \cdot \hat{l}) $$
其中,$k_d$ 和 $I$ 都是分通道的颜色,如果这个颜色是多通道的(例如 RGB),我们需要分别对每个通道进行上述的运算(红色和红色相乘,蓝色和蓝色相乘)。
我们会发现上式有个问题,如果法线和光源方向的夹角超过 $90^\circ$ 时(此时物体表面背对光源),$\hat{n} \cdot \hat{l}$ 会得出一个负数,这个数值是不合法的,因此我们需要修正一下这个模型,当结果小于 $0$ 的时候,我们就直接认为这个分量为 $0$:
$$ L_d = k_d \ I \ \max{}(0,\ \hat{n} \cdot \hat{l}) $$
从下图 3 中我们可以直观感受一下漫反射系数 $k_d$ 对渲染效果产生的影响。可以看到,场景中有一个在左上角的光源,随着 $k_d$ 的增大,场景中的球显得越来越亮。这就是因为不同 $k_d$ 使得对应物体表面对光的反射比例存在区别。另外我们从中也能看到 $\max{}(0,\ \hat{n} \cdot \hat{l})$ 这一项的影响,随着物体表面法线方向光源方向夹角增大,物体表面看起来也会逐步变暗,直至完全变为黑色:

关于上面定义 $L_d$ 的公式还有一点值得一提,注意到上式中完全没有出现相机观察方向 $\hat{v}$,这说明了漫反射分量和观察的方向无关,我们从不同方向去看一个面,它的颜色并不会因此而产生不同。而这本身也符合我们对漫反射分量的定义,漫反射分量本身就是物体表面向周围各个方向反射的光,每一个方向的光都是均匀的,自然和观察的方向没有关系了。
镜面反射分量
镜面反射分量用来模拟光滑物体表面上的高光。光滑物体表面之所以会形成高光是因为它将入射的光线向接近的方向反射,这使得反射的能量比较集中,而不是像粗糙表面那样将能量分散到四面八方。对于一个理想的镜子而言,我们认为其表面无限光滑,其对光线的反射遵从反射定律 4:
- 反射光线、入射光线和反射面在反射发生处的法线位于同一个平面
- 反射角等于入射角
- 反射光线和入射光线处在法线的相对两边
而对于比较光滑的物体,其反射方向也会集中在这个理想镜面反射的方向附近,如下图 5 所示(其中 $R$ 为理想镜面反射方向,黄色区域就是实际的反射范围):
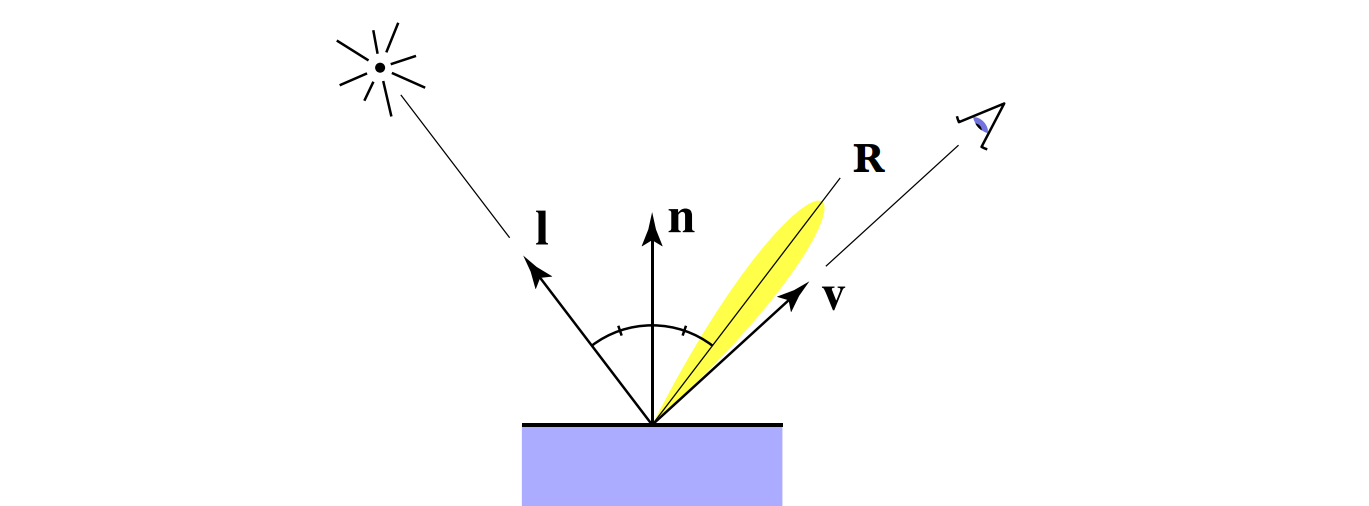
前面的漫反射分量和视角没有关系,而镜面反射分量则和视角有密切的关系。在现实生活中我们也会注意到,当看到一个物体表面反射了刺眼的光线的时候,只要我们稍稍错开一点位置,就不会再感到刺眼了。我们能看到镜面高光的时候,显然就是观察方向 $\hat{v}$ 与这个镜面反射方向接近的时候,在这种情况下,非常多反射光的能量进入了我们的眼睛。我们可以用 $\hat{v} \cdot \hat{R}$ 来计算余弦值以此表示它们是否接近。那么这个反射方向 $R$ 如何计算呢?通过反射定律我们可以知道,入射角和反射角相同,因此我们可以平移反射向量 $\hat{R}$ 使之与 $\hat{l}$ 形成一个等腰三角形,并设 $\hat{l}$ 在 $\hat{n}$ 方向上的投影为 $\vec{s}$,如下图所示:
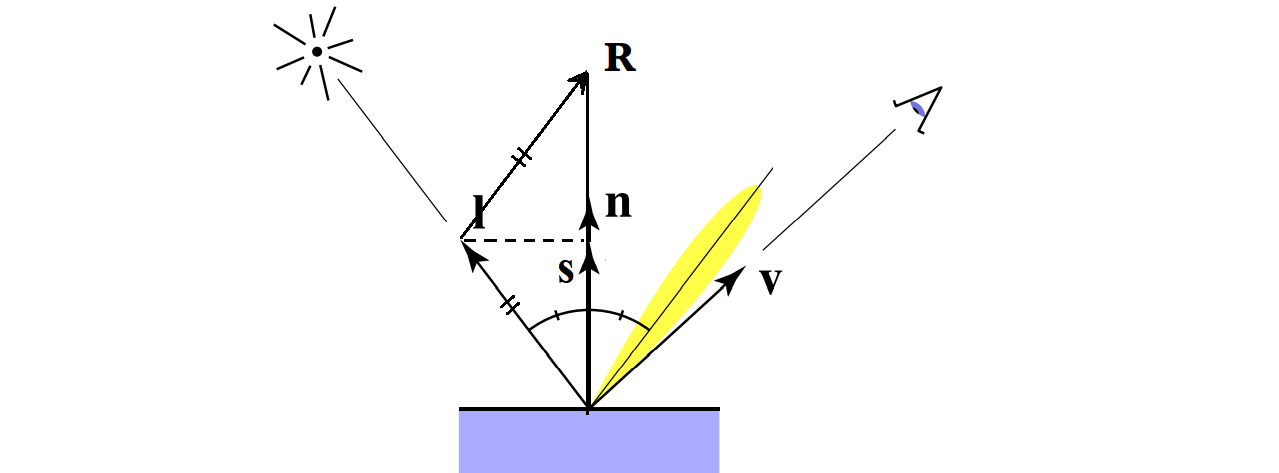
那么根据等腰三角形的性质,我们知道:
$$ \hat{l} + \hat{R} = 2 \ \vec{s} $$
又由于:
$$ \vec{s} = \frac{\left | \hat{l} \right | \cos{\theta}}{\left | \hat{n} \right |} \ \hat{n} $$
其中,$\theta$ 为 $\hat{l}$ 与 $\hat{n}$ 的夹角。我们可以知道(注意 $\hat{n}$ 是单位向量,模长为 $1$):
$$ \vec{s} = \frac{\hat{l} \cdot \hat{n}}{\left | \hat{n} \right | ^2} \ \hat{n} = (\hat{l} \cdot \hat{n}) \ \hat{n} $$
代入 $\vec{s}$ 可知:
$$ \hat{R} = 2 \ (\hat{l} \cdot \hat{n}) \ \hat{n} - \hat{l} $$
求解出反射向量 $\hat{R}$ 后,类似于漫反射,我们也给高光加上一个镜面反射系数 $k_s$,它反映了模型表面高光的强度。除了这个镜面反射系数之外,我们还会在公式中加入一个称为「光亮度」(Shininess)的参数 $p$。稍后我们再来讨论 $p$ 的功能。首先还是先看一下镜面反射分量 $L_s$ 的公式:
$$ L_s = k_s \ I \ \max{}(0,\ \hat{I} \cdot \hat{R})^p $$
类似于漫反射的计算,由于余弦值可能出现负数,我们也需要在当结果小于 $0$ 的时候,直接认为这个分量为 $0$。我们前面提到,这里添加了一个光亮度参数 $p$,这个参数存在的原因是余弦值虽然随着角度的增大会从 $1$ 降到 $0$,但是它的下降速度是相当慢的。下降速度慢就意味着它在很大的角度范围内都为正值,这将导致物体表面上出现很大范围的镜面高光,这和我们平时观察到的情况并不符合。因此我们添加了一个指数项让它的下降速度变快,我们可以通过下图 5 直观了解到指数增大对余弦值下降速度的影响:
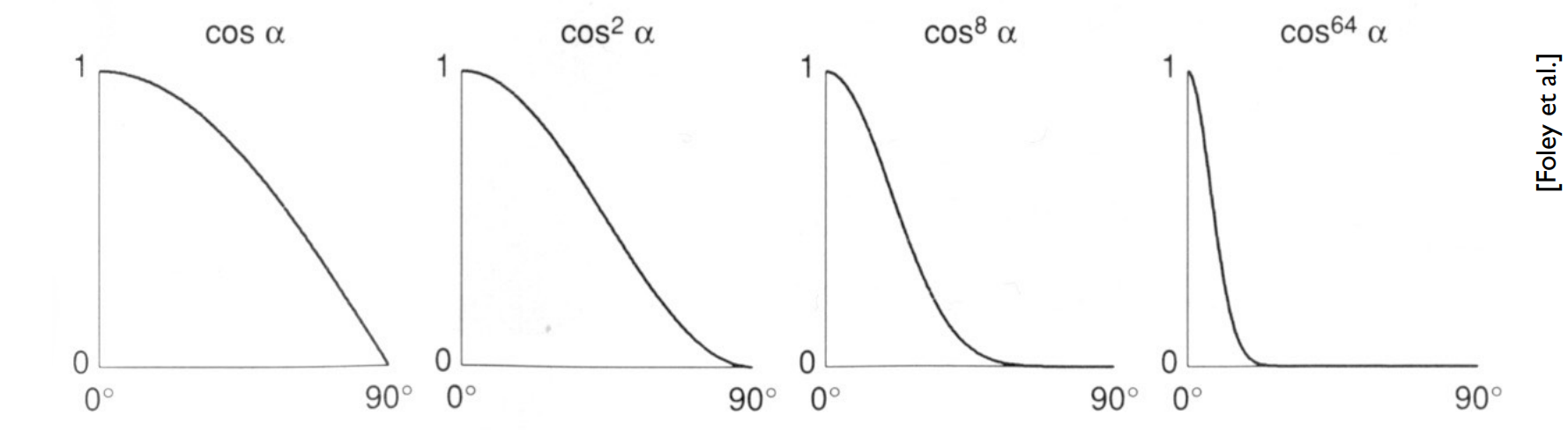
我们可以通过光亮度参数 $p$ 来控制镜面高光的衰减速度,进而控制光斑的大小,$p$ 越大则光斑越小,借此我们可以模拟出不同的表面材质。从下图 5 中我们可以看到光亮度系数 $p$ 和镜面反射系数 $k_s$ 对渲染效果产生的影响。可以看到,随着 $k_s$ 的增大,镜面高光会越来越亮,而随着 $p$ 的增大,镜面高光的范围越来越小:

环境光分量
环境光分量本身应该是最复杂的分量,因为每一个点都会接收到来自周围物体反射而来的光线,这使得一个点即便没有被光源直接照射也能被我们看到。由于光线会在物体间弹射,因此场景中的所有物体都可能对其他着色点的颜色产生贡献,如下图 5 所示:
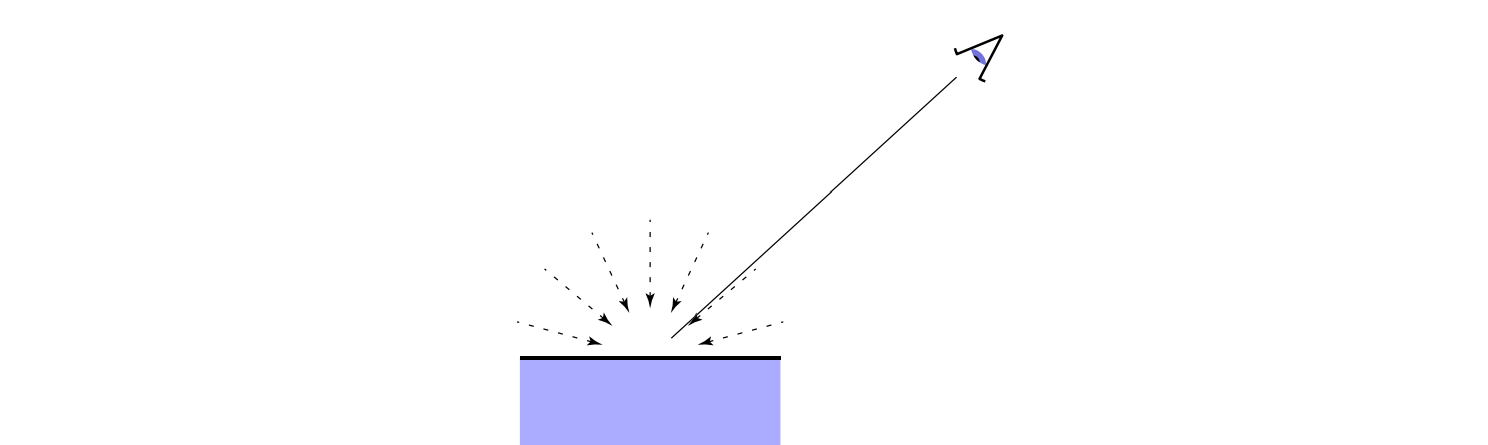
但是正因为它太复杂了,所以 Phong 反射模型对它作了一个非常大胆的简化,使其仅用一个环境光系数 $k_a$ 来控制环境光分量的强度,即:
$$ L_a = k_a \ I $$
从上式中可以看出,环境光分量和光源的方向无关,也和观察方向无关,甚至和法线方向也无关,对于给定的光强 $I$ 而言,环境光分量其实就是个常数,用来将画面整体提亮一点。很显然这完全不符合物理规律,但前面也说过,Phong 反射模型是一个经验模型,使用环境光确实能在一定程度上模拟出环境中的间接光照的效果,而且它的计算量非常低,因此这个取舍是完全可以接受的。
知道三个分量如何计算后,我们只需要将它们加起来,就可以得到 Phong 反射模型的最终结果了:
$$ \begin{align} L &= L_a + L_d + L_s \newline &= k_a I + k_d \ I \ \max{}(0,\ \hat{n} \cdot \hat{l}) + k_s \ I \ \max{}(0,\ \hat{I} \cdot \hat{R})^p \end{align} $$
Blinn-Phong 反射模型
前文讨论的 Phong 模型可以很好地模拟广泛的光照场景,但它在镜面高光的表现上存在一些不足,这个不足之处在光亮度较小的情况下表现得尤为明显。例如下图 6 中的场景(光亮度为 $1.0$):
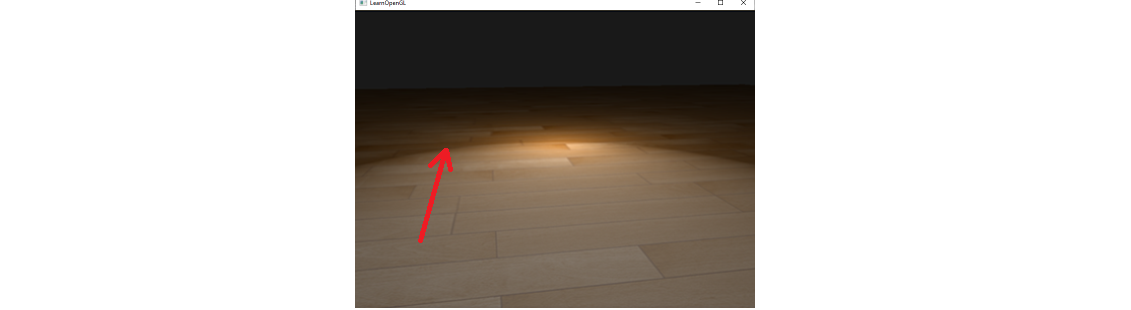
可以看到在红色箭头指向的位置存在一个明显的明暗断层,这是怎么出现的呢?首先,我们回顾一下 Phong 模型的镜面高光项的公式:
$$ L_s = k_s \ I \ \max{}(0,\ \hat{I} \cdot \hat{R})^p $$
这个公式意味着,镜面反射方向和观察方向的夹角一旦超过 $90^\circ$,$L_s$ 就变成了 $0$。这件事情在 $p$ 比较大的时候不会产生太大的影响,因为此时高光衰减很快,还不到 $90^\circ$ 就已经衰减完了,但是如果这个 $p$ 很小,那么高光范围就会很大,我们就容易观察到这个断层。
我们可能会觉得奇怪,这个 $\max{}(0, x)$ 的逻辑不是在计算漫反射项的时候也存在吗?为什么漫反射项就没有这样的问题呢?我们先来回顾一下漫反射项的公式:
$$ L_d = k_d \ I \ \max{}(0,\ \hat{n} \cdot \hat{l}) $$
可以看到,漫反射项所使用的夹角是着色点表面法线方向和光源方向的夹角,如果这个夹角大于 $90^\circ$,那说明光线在着色点表面的背面,此时漫反射项为 $0$ 自然没有什么问题,但是对于镜面高光项而言,情况并不是这样,例如下图中的情况:
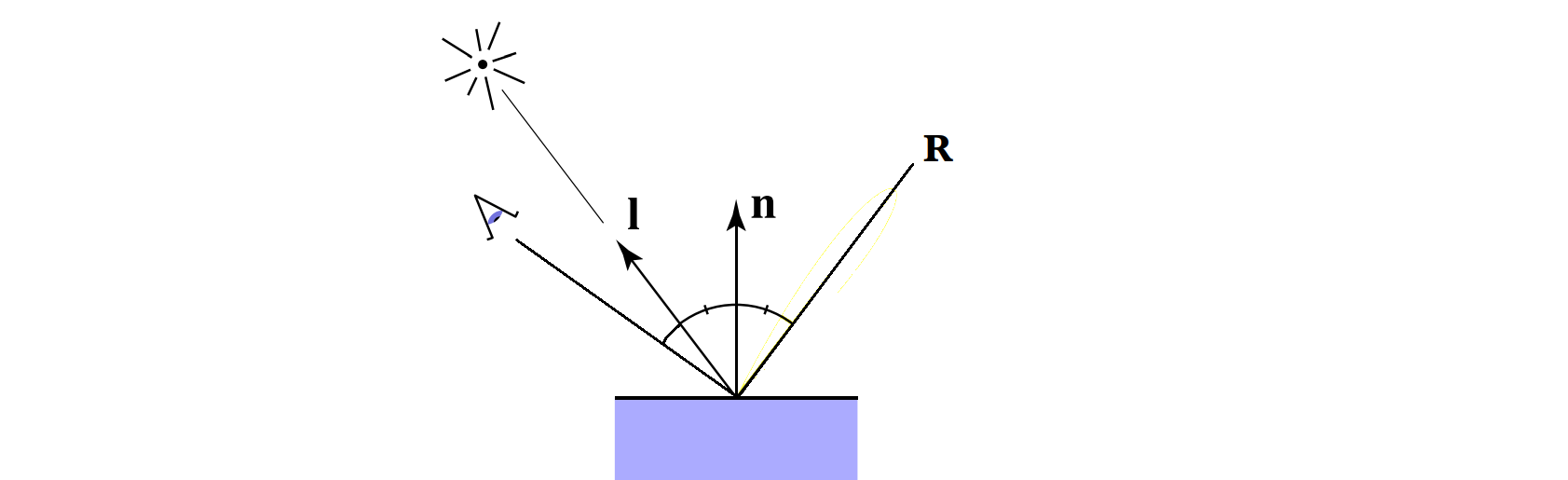
可以看到,在观察方向和光源方向在法线 $\hat{n}$ 的同一侧的时候,确实是有可能出现夹角大于 $90^\circ$ 的情况,这就导致了前面提到的高光断层问题。Blinn-Phong 反射模型对 Phong 反射模型进行了改进,它和 Phong 反射模型的区别仅在于镜面高光分量的计算方式。Blinn-Phong 反射模型并不计算观察方向和镜面反射方向的夹角余弦值,而是计算「半程向量」(Halfway Vector)和着色点表面法线的夹角余弦值。这里的半程向量 $\hat{h}$ 是指光源方向和观察方向中间的方向上的单位向量,如下图 5 所示:
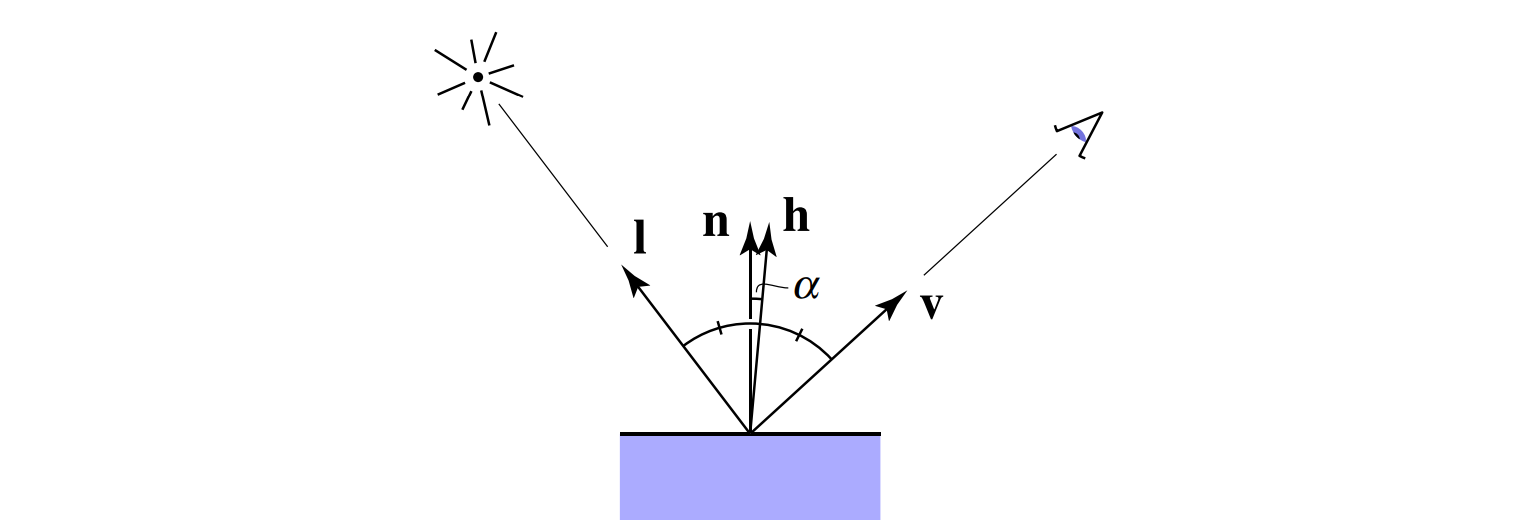
使用这个夹角来源于这样的观察:当观察方向和镜面反射方向的夹角增大时,这个半程向量和法线的夹角也相应增大。而且只要在平面的同一侧,那么这个半程向量和法线的夹角就不会超过 $90^\circ$,这正是我们想要的结果。换用 Blinn-Phong 反射模型之后,效果如下图 6 所示,可以看到前面提到的断层消失了:
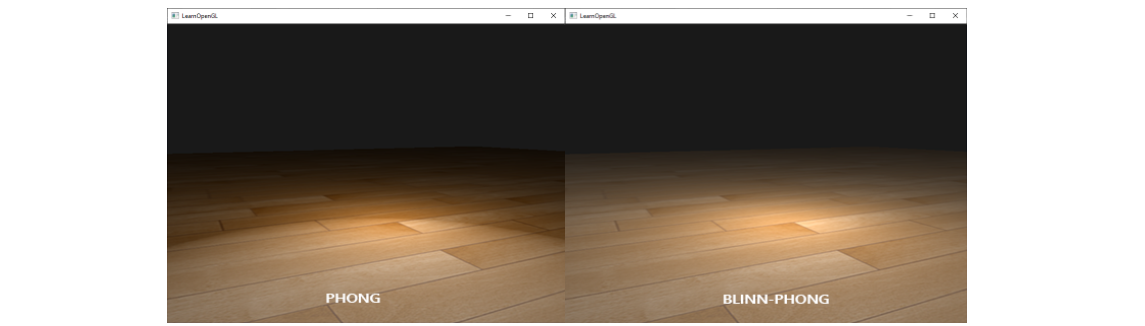
Blinn-Phong 模型还带来了一个很大的好处,还记得我们上面计算反射方向时的麻烦操作么?现在换用 Blinn-Phong 模型后,我们不需要计算如此复杂的反射方向的向量,只需要这样计算半程向量即可:
$$ \hat{h} = \mathrm{bisector}(\hat{l},\ \hat{v}) = \frac{\hat{l} + \hat{v}}{\left | \hat{l} + \hat{v} \right |} $$
另外一点需要注意的是,由于半程向量与着色点表面法线的夹角一般会比观察方向和镜面反射方向的夹角要小,因此我们如果要在 Blinn-Phong 反射模型中实现和 Phong 反射模型类似的镜面高光效果,就需要选用一个更大的光亮度,一般而言会选择 $4$ 倍于 Phong 反射模型中的数值,如下图 7 所示:
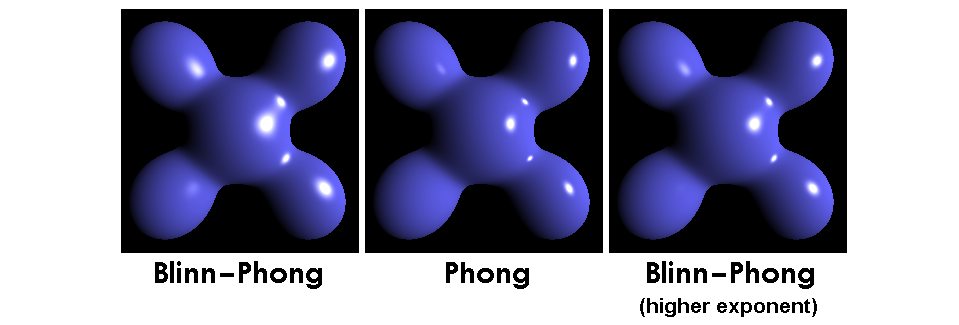
Phong 着色法
前文讨论了如何计算一个着色点的颜色,但对于一个三角形而言,我们一般只会设置其三个顶点的属性,那么三角形中其他着色点的颜色又应该如何计算呢?对于这个问题,不同的着色方式采用了不同的策略,下图 5 展示了几种不同的着色方式所产生的不同渲染效果(图中三个球使用了同样的模型):

最左边的图使用的着色方法是平直着色法(Flat Shading)1,它先在每个多边形上挑选一个点计算颜色(通常是多边形的第一个顶点,如果是三角形也可以选择几何中心),然后对该多边形上其余着色点都直接使用该点的颜色。所以,使用平直着色法的每个多边形上都是统一的颜色。
中间的图使用的着色方法是 Gouraud 着色法(Gouraud Shading)1,它先计算多边形的每个顶点的法向量,然后计算出每个顶点的颜色,对于多边形中间部分的着色点的颜色,则通过顶点计算出的颜色插值得到。可以看到,Gouraud 着色法会在多边形上产生渐变的颜色,效果比平直着色法要更自然一些。这个效果的提升是因为 Gouraud 着色法将着色频率从逐面的着色提升到逐顶点的着色。尽管如此,我们还是能在图中感受到棱角。显然,要想更进一步平滑渲染效果,我们就需要进一步提高着色频率。
最右边的图使用的着色方法是 Phong 着色法(Phong Shading)1,它不是对最终计算出的颜色进行插值,而是在一开始就对法线进行插值得出每一个着色点的法线,然后再用这个信息对每一个着色点计算颜色。在这三种着色法中,Phong 着色法有着最高的着色频率(逐着色点着色),也因此有最平滑的视觉效果。需要注意的是,这里说的 Phong 着色法和前文说的 Phong 反射模型不是一回事,只是恰好都是 Bui Tuong Phong 8 提出的,因此都冠有他的名字。
Gouraud 着色法和 Phong 着色法都涉及了数据的「插值」计算,这个处理方式在渲染的过程中非常常用。正如我们刚刚提到的,在实际应用中,许多模型属性(例如法线信息)是逐顶点指定的,而出于各方面的成本考虑,我们不可能为了达到视觉上的平滑效果而无限将模型变得精细,因此我们会对顶点之间的点的属性进行插值计算。例如在 Phong 着色法中我们对法线进行插值,在使用纹理的时候也会对 UV 坐标进行插值,下面我们就来讨论一下在三角形中这个插值如何计算。
基于重心坐标插值
我们这里讨论的重心坐标 9,是由三角形顶点定义的坐标系。也就是给定一个三角形,我们有一个重心坐标系,换一个三角形则坐标系也会跟着变换。给定一个三角形 $\triangle_{ABC}$,对于其中任意一点 $(x,\ y)$,我们都可以将这个点的坐标表示为三角形三个顶点的坐标的线性组合,即:
$$ (x,\ y) = \alpha \ (x_A,\ y_A) + \beta \ (x_B,\ y_B) + \gamma \ (x_C,\ y_C) $$
其中
$$ \alpha + \beta + \gamma = 1 $$
此时,我们就用坐标 $(\alpha,\ \beta,\ \gamma)$ 来描述 $(x,\ y)$ 的位置,这个 $(\alpha,\ \beta,\ \gamma)$ 就被称为重心坐标。而且,只要 $(x,\ y)$ 在三角形内,则 $\alpha$、$\beta$ 和 $\gamma$ 的范围都是 $[0,\ 1]$。显然,由于存在 $\alpha + \beta + \gamma = 1$ 的限制,其实重心坐标只需要其中两个值即可确定,剩下一个值可以直接被算出来。
通过以上定义,我们很容易知道三角形 $\triangle_{ABC}$ 的三个顶点 $A$、$B$、$C$ 的重心坐标分别为 $(1,\ 0,\ 0)$、$(0,\ 1,\ 0)$ 和 $(0,\ 0,\ 1)$。那么对于任意点的重心坐标我们怎么算呢?这里给出重心坐标的几何视角的定义,对于任意三角形而言,将待求的点 $(x,\ y)$ 与该三角形的每个顶点连线,此时会形成三个三角形。设与顶点 $X$ 不相邻的三角形的面积为 $A_X$,如下图 10 所示:
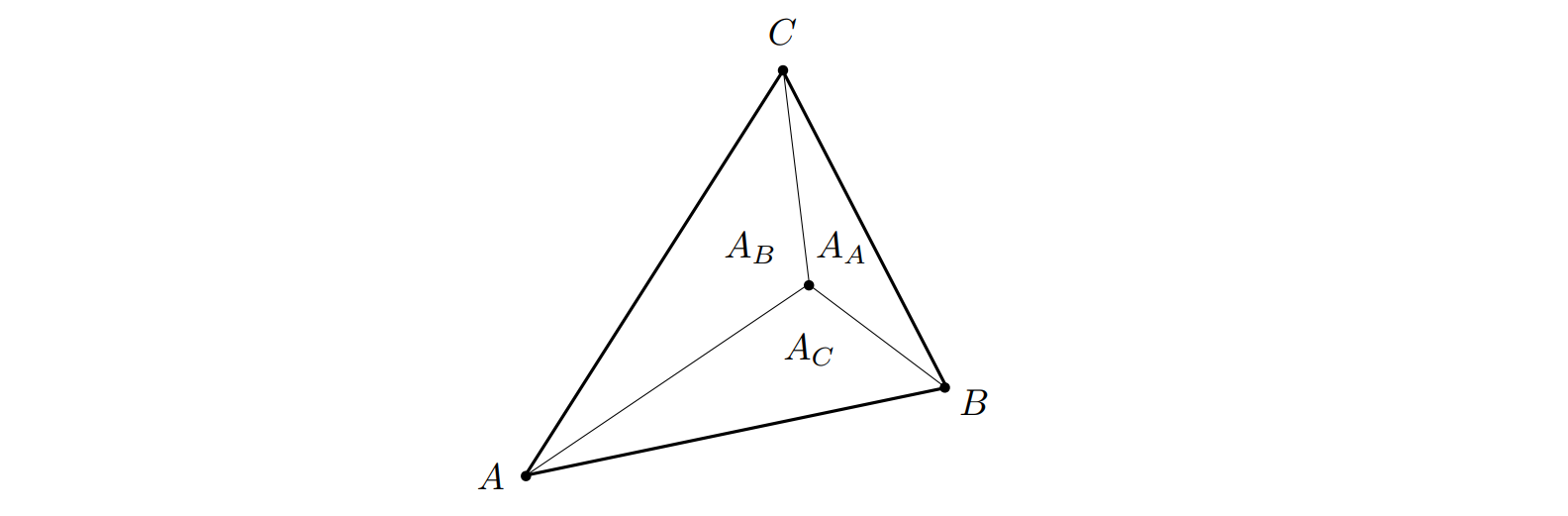
则我们有:
$$ \begin{align} \alpha &= \frac{A_A}{A_A + A_B + A_C} \newline \beta &= \frac{A_B}{A_A + A_B + A_C} \newline \gamma &= \frac{A_C}{A_A + A_B + A_C} \end{align} $$
基于上面的定义,代入三角形面积的计算公式 11,我们可以推出该点的重心坐标可以表示为:
$$ \begin{align} \alpha &= \frac{-(x - x_B) \ (y_C - y_B) + (y - y_B) \ (x_C - x_B)}{-(x_A - x_B) \ (y_C - y_B) + (y_A - y_B) \ (x_C - x_B)} \newline \beta &= \frac{-(x - x_C) \ (y_A - y_C) + (y - y_C) \ (x_A - x_C)}{-(x_B - x_C) \ (y_A - y_C) + (y_B - y_C) \ (x_A - x_C)} \newline \gamma &= 1 - \alpha - \beta \end{align} $$
知道重心坐标如何计算后,我们就可以直接用重心坐标作为顶点属性的权重,来计算出任意一点的属性了。假设三角形 $\triangle_{ABC}$ 的三个顶点分别有属性 $I_A$、$I_B$ 和 $I_C$,那么对于任意重心坐标为 $(\alpha,\ \beta,\ \gamma)$ 的点,其对应的属性就为 $I = \alpha \ I_A + \beta \ I_B + \gamma \ I_C$。这个「属性」可以是任意属性,例如法线、颜色、深度等等,都可以用同样的方式进行插值。
重心坐标插值修正
重心坐标计算简单,但是它有一个问题,就是它在透视变换下并不能保持不变,这使得我们插值出来的结果会很奇怪。要知道这个问题是如何发生的,我们可以看下图 12 所示的情况:
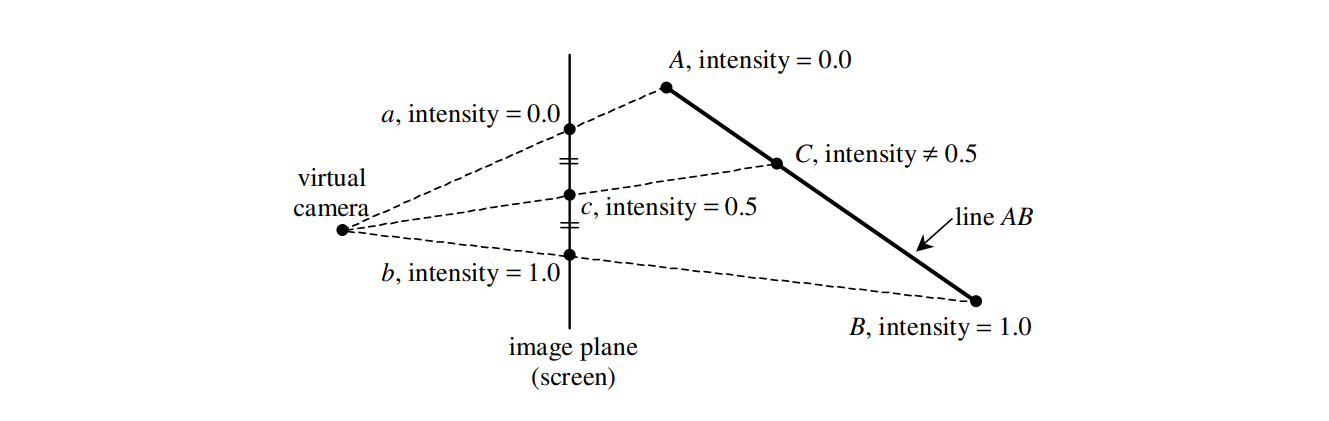
在上图中,线段 $AB$ 投影到投影面上形成了线段 $ab$,我们取线段 $ab$ 的中点 $c$,然后连接并延长相机所在位置和点 $c$,与 $AB$ 交与一点 $C$,此时,我们会发现,由于 $AB$ 并不平行于投影面,因此 $C$ 并不是 $AB$ 的中点。这导致了如果我们直接对 $ab$ 进行插值算出每个像素点的属性,插值的结果会和三维空间中的插值结果不匹配。因此,我们需要对插值的结果进行修正。
为了方便说明,我们只看 $x$ 轴和 $z$ 轴的情况,设点 $A$ 的坐标为 $(X_1,\ Z_1)$,点 $B$ 的坐标为 $(X_2,\ Z_2)$,设相机与投影平面距离为 $d$,$A$、$B$ 对应投影到投影平面上的点 $a$ 和点 $b$ 的坐标分别为 $(u_1,\ d)$ 和 $(u_2,\ d)$。当我们要插值投影平面上的点 $c$ $(u_s,\ d)$ 的时候,我们其实要计算的是三维空间中点 $C$ $(X_t,\ Z_t)$ 的属性值 $I_t$。如下图 12 所示:
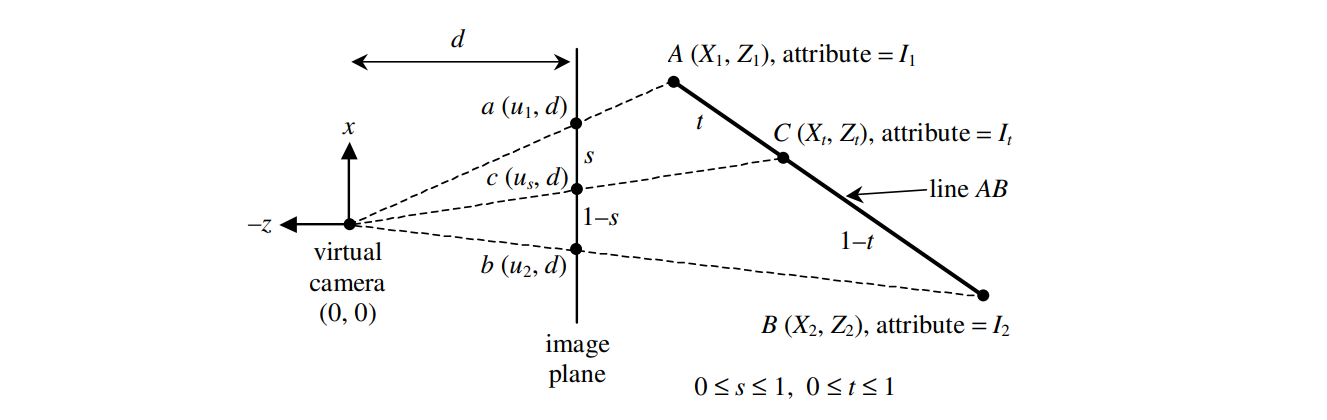
根据相似三角形的特性,我们有:
$$ \begin{align} \frac{X_1}{Z_1} = \frac{u_1}{d} \quad & \Rightarrow \quad X_1 = \frac{u_1}{d} \ Z_1 \newline \frac{X_2}{Z_2} = \frac{u_2}{d} \quad & \Rightarrow \quad X_2 = \frac{u_2}{d} \ Z_2 \newline \frac{X_t}{Z_t} = \frac{u_s}{d} \quad & \Rightarrow \quad X_t = \frac{u_s}{d} \ Z_t \end{align} $$
根据插值计算的逻辑,我们有:
$$ \begin{align} u_s &= s \ u_2 + (1 - s) \ u_1 \newline X_t &= t \ X_2 + (1 - t) \ X_1 \newline Z_t &= t \ Z_2 + (1 - t) \ Z_1 \end{align} $$
根据 $Z_t = dX_t/u_s$,可得:
$$ \begin{align} Z_t &= \frac{d}{u_1 + s \ (u_2 - u_1)} \ (X_1 + t \ (X_2 - X_1)) \newline &= \frac{d}{u_1 + s \ (u_2 - u_1)} \ \left( \frac{u_1}{d} \ Z_1 + t \ \left( \frac{u_2}{d} \ Z_2 - \frac{u_1}{d} \ Z_1 \right) \right) \newline &= \frac{u_1 \ Z_1 + t \ (u_2 \ Z_2 - u_1 \ Z_1)}{u_1 + s \ (u_2 - u_1)} \end{align} $$
因此我们有:
$$ Z_1 + t \ (Z_2 - Z_1) = \frac{u_1 \ Z_1 + t \ \left( u_2 \ Z_2 - u_1 \ Z_1 \right)}{u_1 + s \ (u_2 - u_1)} $$
化简可得:
$$ t = \frac{s \ Z_1}{s \ Z_1 + (1 - s) \ Z_2} $$
因此我们可以得到 $Z_t$ 正确的计算方法为:
$$ \begin{align} Z_t &= t \ Z_2 + (1 - t) \ Z_1 \newline &= \frac{1}{\frac{1}{Z_1} + s \ (\frac{1}{Z_2} - \frac{1}{Z_1})} \end{align} $$
类似于 $Z_t$,对于任意的属性 $I$(可以是任何属性,如法线、颜色等)而言,插值的 $I_t$ 可以由如下方式计算:
$$ I_t = t \ I_2 + (1 - t) \ I_1 $$
同样代入 $t$ 的值,可得:
$$ \begin{align} I_t &= I_1 + \frac{s \ Z_1}{s \ Z_1 + (1 - s) \ Z_2} \ (I_2 - I_1) \newline &= \left. \left( \frac{I_1}{Z_1} + s \left( \frac{I_2}{Z_2} - \frac{I_1}{Z_1} \right) \right) \middle/ \left( \frac{1}{Z_1} + s \left( \frac{1}{Z_2} - \frac{1}{Z_1} \right) \right) \right. \end{align} $$
我们可以发现,这个被除数正好就是刚刚计算出来的 $Z_t$ 的倒数,代入可得:
$$ I_t = \left. \left( \frac{I_1}{Z_1} + s \left( \frac{I_2}{Z_2} - \frac{I_1}{Z_1} \right) \right) \middle/ \frac{1}{Z_t} \right. $$
根据这个公式,我们就能知道如何计算正确的顶点属性插值了。对于任意需要插值的顶点属性 $I$ 而言,设其对应的深度值为 $Z$,那么我们应该先对 $I/Z$ 进行插值,然后将结果再除以 $1/Z$ 插值的结果,使用这样的方法插值出来的顶点属性才是透视正确的插值结果。